Declaration Chains for Name Analysis
I made a very nice and efficient name analysis system for a compiler that I am working on. I have not seen this method of doing name analysis before so I will try to describe how it works in this post. It is possible that this is a common idea that I just have not encountered before.
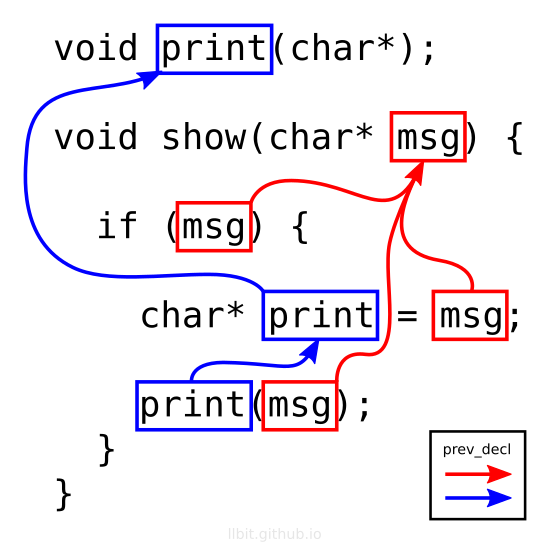
In name analysis it is common to use one hash table for each name scope, but in my system I use only a single hash table and two stacks.
The idea is to store name bindings in declaration chains: each declaration node having a pointer to the previous declaration. The previous declaration points to the previously declared name from the point of the new declaration.
The declaration chains are kept intact after name analysis is finished so that I can use the chains to iterate over visible names. Name uses are bound to declaration chains so that call resolution and duplicate declaration checking can be done with the declaration chain.
In my case the AST nodes are objects of struct AstNode. This contains
declaration chains as intrusive singly linked lists with a
pointer pointing to the previous declaration:
struct AstNode {
...
AstNode* prev_decl; // Previous declaration with same name.
};
The current head of the declaration chain for each name is stored in a global
hash table that maps declaration names to declaration nodes. Initially this
hash table is empty and all prev_decl pointers are NULL.
To handle scoping of names we need two stacks - one stores all declarations that are visible (but possibly shadowed by more recent declarations). The other stack stores the number of names that were declared in the current scope. We need to know the number of local declarations for each scope when unwinding the declaration stack.
The data for name analysis is stored like this:
struct State {
HashTable* names; // Current head of each name chain.
// Name stack:
AstNode* stack;
int stack_last; // Initially 0.
// Number of names in each scope:
int* scope;
int scope_last; // Initially 0.
};In reality the stacks use their own data structures that can grow dynamically but I’ve simplified it to fixed-sized arrays here for simplicity.
When doing name analysis the AST is visited in a pre-order traversal and each time a new declaration is encountered we have to update the hash table to point to the new head of the corresponding declaration chain.
The functions below illustrate how the name analysis works. The declare
function is called once for each declaration node during the AST name analysis
traversal. The push_scope function is called whenever we enter a new name
scope and pop_scope is called when leaving the scope.
/** Get the name of a declaration. */
const char* ast_decl_name(const AstNode* decl);
void declare(State s, AstNode* decl)
{
const char* name = ast_decl_name(decl);
decl->prev_decl = tbl_lookup(s.names, name);
tbl_insert(s.names, name, decl);
s.stack[s.stack_last++] = decl;
s.scope[s.scope_last] += 1;
}
void push_scope(State s)
{
s.scope[++s.scope_last] = 0;
}
void pop_scope(State s)
{
for (int i = 0; i < s.scope[s.scope_last]; ++i) {
AstNode* decl = s.stack[s.stack_last--];
tbl_insert(s.names, ast_decl_name(decl), decl->prev_decl);
}
s.scope_last -= 1;
}During name analysis each non-declaration use of a name is bound to the
matching declaration chain by doing tbl_lookup(s.names, name) to get the
current head of the matching name chain.